
俗话说一图胜千言万语,想了解Storm的话,先来看几张图,直观的了解一下Storm。图片有官方的图片,也有技术人自己画的图片,均来自互联网,在看代码之前先来简单的看一下图片。请快速的看一下图片,找一下感觉,如果一下子看不明白,其实也没有关系。图片流之后,会有一小段文字说明。本文适合Storm小白看,大神吐槽或在1秒内关掉。
Storm历险记之浅入浅出:Storm Hello World入门示例
图1
Storm历险记之浅入浅出:Storm Hello World入门示例
图2
Storm历险记之浅入浅出:Storm Hello World入门示例
图3
Storm历险记之浅入浅出:Storm Hello World入门示例
图4
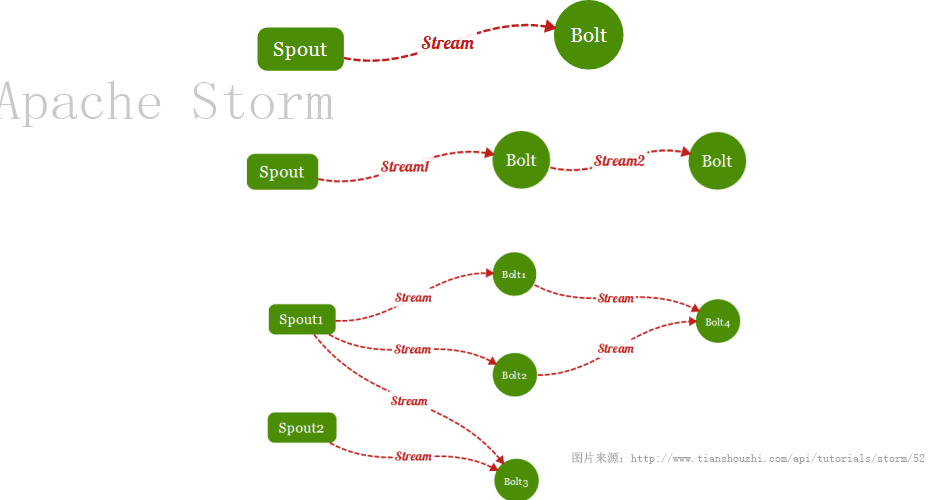
Storm历险记之浅入浅出:Storm Hello World入门示例
图5
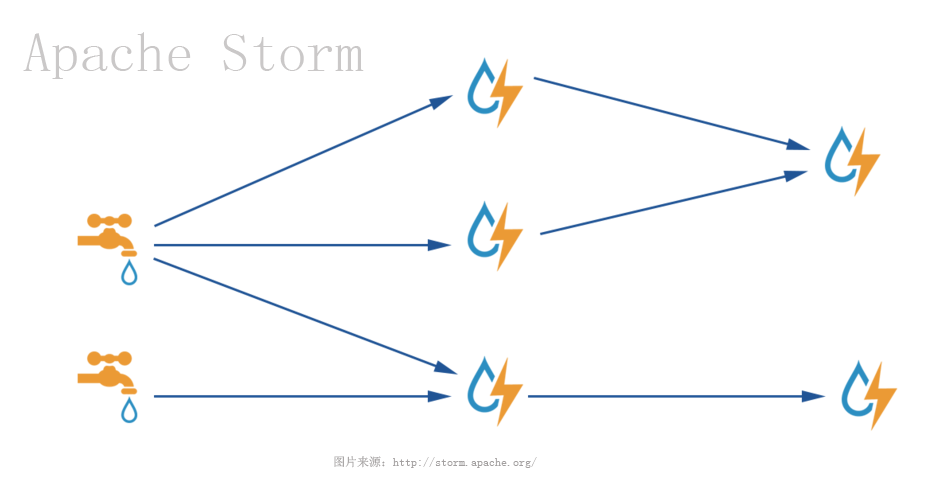
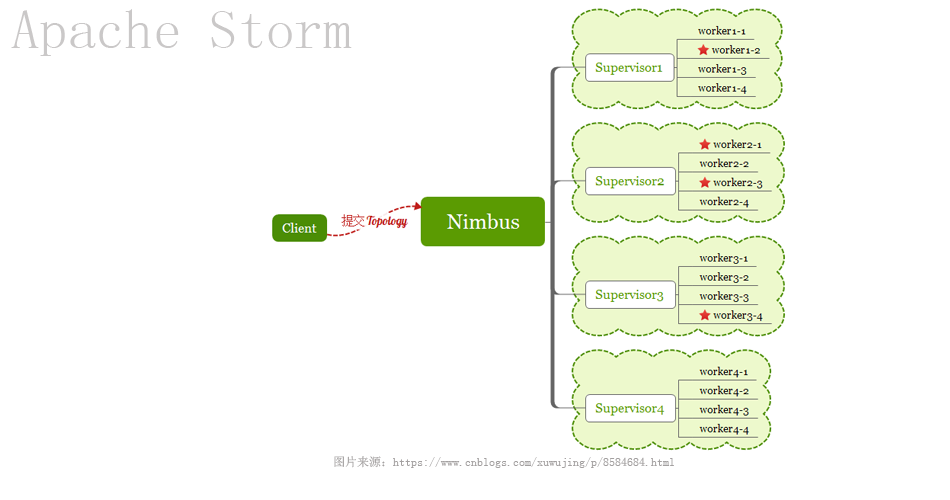
Storm是实时流式处理计算框架,不断的取数据,不断的处理数据,这个过程就像水流一样。官方配图就是一个水龙头来诠释Storm内涵。数据处理流程的开始是Spout,取数据,中间的过程是多个Bolt组合,Bolt是处理数据的单元,Spout与Bolt就像流程图的开始与中间处理过程。Spout与Bolt组合成了一个topology作业,丢给storm就能跑起来。Storm有本地模式,也有远程模式,今天的Storm Hello World采用本地模式。
代码结构:
图6
代码源自https://www.cnblogs.com/xuwujing/p/8584684.html,因为用的最新的storm-core 1.2.2,代码有些改变。从eclipse报错提示来看,store代码中原来 superclass中的部分方法被移到了interfase中,所以有些@Override要去掉。
POM文件
<!– https://mvnrepository.com/artifact/ring-cors/ring-cors –>
<dependency>
<groupId>ring-cors</groupId>
<artifactId>ring-cors</artifactId>
<version>0.1.12</version>
</dependency>
<!– https://mvnrepository.com/artifact/org.apache.storm/storm-core –>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.2</version>
<scope>provided</scope>
</dependency>
修正过的代码
TestSpout
| import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values;
public class TestSpout extends BaseRichSpout{
private static final long serialVersionUID = 225243592780939490L;
private SpoutOutputCollector collector; private static final String field=”word”; private int count=1; private String[] message = { “Storm Hello World”, “http://www.jishudao.com storm blog”, “Play with storm” };
/** * open()方法中是在ISpout接口中定义,在Spout组件初始化时被调用。 * 有三个参数: * 1.Storm配置的Map; * 2.topology中组件的信息; * 3.发射tuple的方法; */ public void open(Map map, TopologyContext arg1, SpoutOutputCollector collector) { System.out.println(“open:”+map.get(“test”)); this.collector = collector; }
/** * nextTuple()方法是Spout实现的核心。 * 也就是主要执行方法,用于输出信息,通过collector.emit方法发射。 */ public void nextTuple() {
if(count<=message.length){ System.out.println(“第”+count +”次开始发送数据…”); this.collector.emit(new Values(message[count-1])); } count++; }
/** * declareOutputFields是在IComponent接口中定义,用于声明数据格式。 * 即输出的一个Tuple中,包含几个字段。 */ public void declareOutputFields(OutputFieldsDeclarer declarer) { System.out.println(“定义格式…”); declarer.declare(new Fields(field)); }
/** * 当一个Tuple处理成功时,会调用这个方法 */ @Override public void ack(Object obj) { System.out.println(“ack:”+obj); }
/** * 当Topology停止时,会调用这个方法 */ @Override public void close() { System.out.println(“关闭…”); }
/** * 当一个Tuple处理失败时,会调用这个方法 */ @Override public void fail(Object obj) { System.out.println(“失败:”+obj); }
} |
TestBolt
| import java.util.Map;
import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values;
public class TestBolt extends BaseRichBolt{
/** * */ private static final long serialVersionUID = 4743224635827696343L;
private OutputCollector collector;
/** * 在Bolt启动前执行,提供Bolt启动环境配置的入口 * 一般对于不可序列化的对象进行实例化。 * 注:如果是可以序列化的对象,那么最好是使用构造函数。 */ public void prepare(Map map, TopologyContext arg1, OutputCollector collector) { System.out.println(“prepare:”+map.get(“test”)); this.collector=collector; }
/** * execute()方法是Bolt实现的核心。 * 也就是执行方法,每次Bolt从流接收一个订阅的tuple,都会调用这个方法。 */ public void execute(Tuple tuple) { String msg=tuple.getStringByField(“word”); System.out.println(“开始分割单词:”+msg); String[] words = msg.toLowerCase().split(” “); for (String word : words) { this.collector.emit(new Values(word));//向下一个bolt发射数据 }
}
/** * 声明数据格式 */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields(“count”)); }
/** * cleanup是IBolt接口中定义,用于释放bolt占用的资源。 * Storm在终止一个bolt之前会调用这个方法。 */ @Override public void cleanup() { System.out.println(“TestBolt的资源释放”); } } |
Test2Bolt
| import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple;
public class Test2Bolt extends BaseRichBolt{
/** * */ private static final long serialVersionUID = 4743224635827696343L;
/** * 保存单词和对应的计数 */ private HashMap<String, Integer> counts = null;
private long count=1; /** * 在Bolt启动前执行,提供Bolt启动环境配置的入口 * 一般对于不可序列化的对象进行实例化。 * 注:如果是可以序列化的对象,那么最好是使用构造函数。 */ public void prepare(Map map, TopologyContext arg1, OutputCollector collector) { System.out.println(“prepare:”+map.get(“test”)); this.counts=new HashMap<String, Integer>(); }
/** * execute()方法是Bolt实现的核心。 * 也就是执行方法,每次Bolt从流接收一个订阅的tuple,都会调用这个方法。 * */ public void execute(Tuple tuple) { String msg=tuple.getStringByField(“count”); System.out.println(“第”+count+”次统计单词出现的次数”); /** * 如果不包含该单词,说明在该map是第一次出现 * 否则进行加1 */ if (!counts.containsKey(msg)) { counts.put(msg, 1); } else { counts.put(msg, counts.get(msg)+1); } count++; }
/** * cleanup是IBolt接口中定义,用于释放bolt占用的资源。 * Storm在终止一个bolt之前会调用这个方法。 */ @Override public void cleanup() { System.out.println(“===========开始显示单词数量============”); for (Map.Entry<String, Integer> entry : counts.entrySet()) { System.out.println(entry.getKey() + “: ” + entry.getValue()); } System.out.println(“===========结束============”); System.out.println(“Test2Bolt的资源释放”); }
/** * 声明数据格式 */ public void declareOutputFields(OutputFieldsDeclarer arg0) {
} }
|
App
| import org.apache.storm.Config;
import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields;
public class App {
private static final String test_spout=”test_spout”; private static final String test_bolt=”test_bolt”; private static final String test2_bolt=”test2_bolt”;
public static void main(String[] args) { //定义一个拓扑 TopologyBuilder builder=new TopologyBuilder(); //设置一个Executeor(线程),默认一个 builder.setSpout(test_spout, new TestSpout(),1); //shuffleGrouping:表示是随机分组 //设置一个Executeor(线程),和一个task builder.setBolt(test_bolt, new TestBolt(),1).setNumTasks(1).shuffleGrouping(test_spout); //fieldsGrouping:表示是按字段分组 //设置一个Executeor(线程),和一个task builder.setBolt(test2_bolt, new Test2Bolt(),1).setNumTasks(1).fieldsGrouping(test_bolt, new Fields(“count”)); Config conf = new Config(); conf.put(“test”, “test”); try{ //运行拓扑 if(args !=null&&args.length>0){ //有参数时,表示向集群提交作业,并把第一个参数当做topology名称 System.out.println(“运行远程模式”); StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); } else{//没有参数时,本地提交 //启动本地模式 System.out.println(“运行本地模式”); LocalCluster cluster = new LocalCluster(); cluster.submitTopology(“Word-counts” ,conf, builder.createTopology() ); Thread.sleep(20000); // //关闭本地集群 cluster.shutdown(); } }catch (Exception e){ e.printStackTrace(); } } } |
踩坑 The POM for ring-cors:ring-cors:jar:0.1.5 is missing
解决办法:
https://mvnrepository.com/artifact/ring-cors/ring-cors/0.1.12
直接把ring-cors-0.1.12.jar ring-cors-0.1.12.pom下载下来,放到maven本地库中。
有初步的Hello World感觉之后,可以再详细看看官方的资料,除了看别人翻译的,强烈建议对比着官方的看。官方有详细的文档清单,不要着急,一个一个慢慢看。
Basics of Storm
- Javadoc
- Concepts
- Scheduler
- Configuration
- Guaranteeing message processing
- Daemon Fault Tolerance
- Command line client
- REST API
- Understanding the parallelism of a Storm topology
- FAQ
Layers on top of Storm
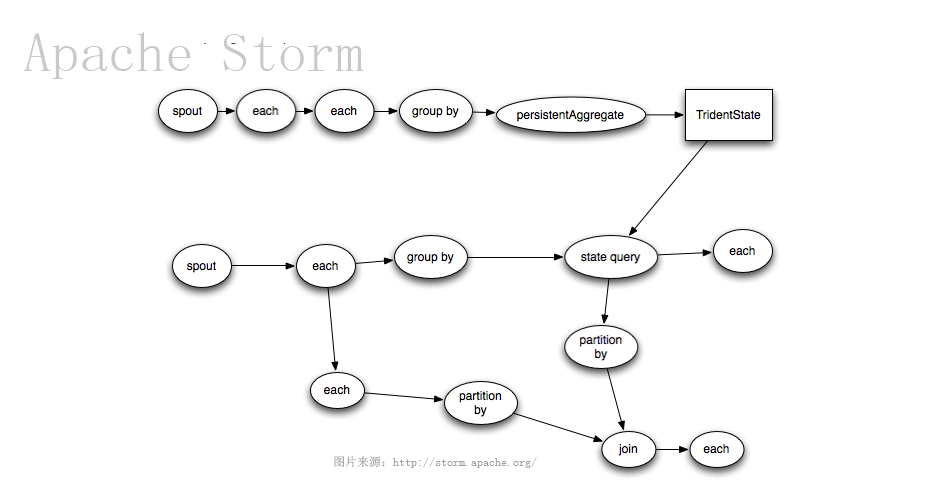
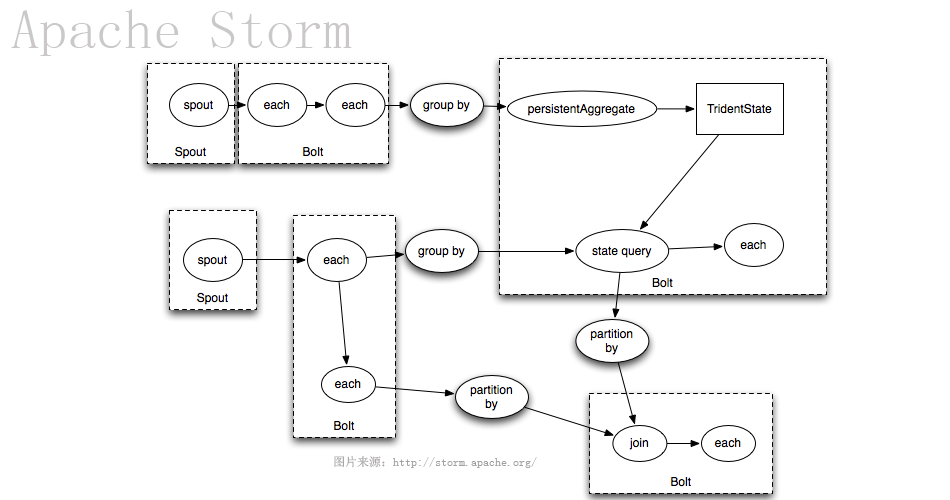
Trident
Trident is an alternative interface to Storm. It provides exactly-once processing, “transactional” datastore persistence, and a set of common stream analytics operations.
- Trident Tutorial — basic concepts and walkthrough
- Trident API Overview — operations for transforming and orchestrating data
- Trident State — exactly-once processing and fast, persistent aggregation
- Trident spouts — transactional and non-transactional data intake
- Trident RAS API — using the Resource Aware Scheduler with Trident.
Streams API
Stream APIs is another alternative interface to Storm. It provides a typed API for expressing streaming computations and supports functional style operations.
NOTE: Streams API is an experimental feature, and further works might break backward compatibility. We’re also notifying it via annotating classes with marker interface @InterfaceStability.Unstable.
SQL
The Storm SQL integration allows users to run SQL queries over streaming data in Storm.
NOTE: Storm SQL is an experimental feature, so the internals of Storm SQL and supported features are subject to change. But small change will not affect the user experience. We will notify the user when breaking UX change is introduced.
Flux
Setup and Deploying
- Setting up a Storm cluster
- Local mode
- Troubleshooting
- Running topologies on a production cluster
- Building Storm with Maven
- Setting up a Secure Cluster
- CGroup Enforcement
- Pacemaker reduces load on zookeeper for large clusters
- Resource Aware Scheduler
- Daemon Metrics/Monitoring
- Windows users guide
- Classpath handling
Intermediate
- Serialization
- Common patterns
- DSLs and multilang adapters
- Using non-JVM languages with Storm
- Distributed RPC
- Transactional topologies
- Hooks
- Metrics (Deprecated)
- Metrics V2
- State Checkpointing
- Windowing
- Joining Streams
- Blobstore(Distcahce)
Debugging
Integration With External Systems, and Other Libraries
- Apache Kafka Integration, New Kafka Consumer Integration
- Apache HBase Integration
- Apache HDFS Integration
- Apache Hive Integration
- Apache Solr Integration
- Apache Cassandra Integration
- Apache RocketMQ Integration
- JDBC Integration
- JMS Integration
- MQTT Integration
- Redis Integration
- Event Hubs Intergration
- Elasticsearch Integration
- Mongodb Integration
- OpenTSDB Integration
- Kinesis Integration
- Druid Integration
- PMML Integration
- Kestrel Integration
Container, Resource Management System Integration
Advanced
- Defining a non-JVM language DSL for Storm
- Multilang protocol (how to provide support for another language)
- Implementation docs
- Storm Metricstore
本文适合Storm小白看,大神吐槽或在1秒内关掉。也适合.net转java的软件工程师查看。建议先照流程跑起代码,再自己照着示例一行一行敲一遍,感受一下storm关键词,加深印象。不能带你深入浅出,只能浅入浅出。我也刚看,欢迎关注公众号,一直学习成长!

参考与引用: