


提到实现搜索功能,很快就想到sql的like模糊查找 ,很快就想到Lucene、Elasticsearch、solr,这些都是要实现搜索功能的关键术语。今天将分享的是采用Elasticsearch打造自主站内搜索引擎的实战经验分享。本文不是讲原理,不是分析es源代码,也不是讲es故事的,仅从应用角度,带小白运用es打造一个简易的搜索引擎。
一、为什么要使用elasticsearch
选elasticsearch,冲着开源免费,内置Lucene分词,在主自搜索引擎这块,es还是很有名气的。相比较于关系型数据库,elasticsearch倒排索引,能有更加高效的搜索性能。对于一般企业来讲,重复造轮子的成本太大,使用es算是一个不错的选择。
二、自主搜索引擎的基本组成
自主搜索引擎主要由elaticsearch安装、数据同步服务与Elastic Search High level API三大块组成。下面分别介绍这三大块。
2.0 安装elasticsearch
安装教程之前有专门写了一个小白序列,可以参考。
Storm Topology : Elasticsearch & Redis 构建实时性低延时数据统计分析 呈现大数据分析效果
2.1 数据同步服务 建立es索引
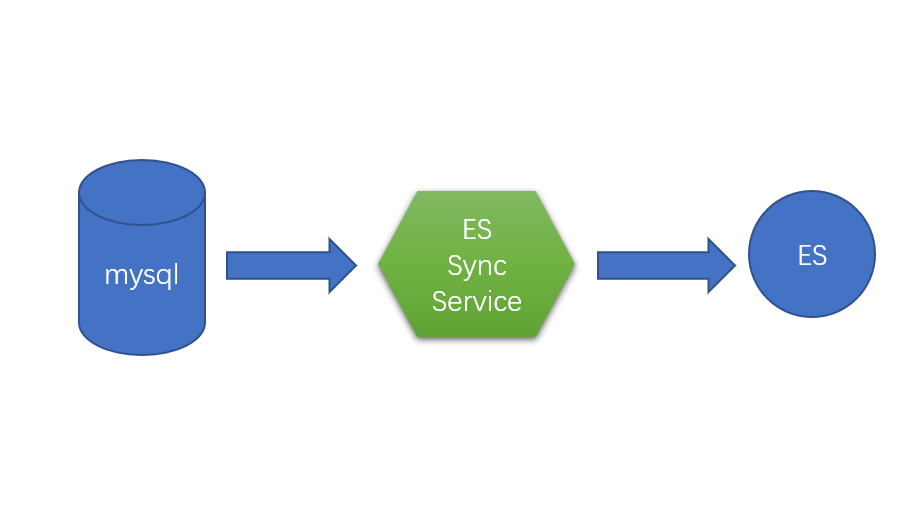
数据同步服务,即将需要用于搜索展示的数据组装好,同步到es,这个过程是利用es建立索引的过程。服务一般以后台服务的形式定时执行。我们的做法是,针对需要查询的数据,写操作日志,包括增、删、改操作,同步服务定时检查日志,将数据同步到es上。一般是多个表组合好的业务数据,对应es上的一个索引类型。若是同步服务写得好,应该可以将同步服务做成透明的,通过配置,直接将数据对接到es,显然,我们没有造这种“面包机”,我们在mysql里有建立操作日志,专门用于es同步。同步服务会记录操作日志进度,不断同步业务数据到es.基本上,写完这个服务,基本上就完成很大一块工作了,成功的希望就在眼前。
关注ChinaHadoop公众号,回复”Elasticsearch”可获取一份《创建index和type.txt》
2.2 使用elasticsearch High Level API查询数据
准备好了同步服务,有了索引数据,接下来就是使用数据了。在这里推荐使用的是elasticsearch High Level API,为什么不推荐其他api或映射框架?因为我就会这一种方式啊!算是抛砖引玉,想了解更的方式,可以关注公众号,期待下一个回合。
你可能会见到的包引用,以java为例
POM包
<!-- elasticsearch.client --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>6.7.2</version></dependency>
import org.elasticsearch.action.DocWriteResponse;import org.elasticsearch.action.delete.DeleteRequest;import org.elasticsearch.action.delete.DeleteResponse;import org.elasticsearch.action.index.IndexRequest;import org.elasticsearch.action.index.IndexResponse;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.action.update.UpdateRequest;import org.elasticsearch.action.update.UpdateResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.common.unit.TimeValue;import org.elasticsearch.common.xcontent.XContentType;import org.elasticsearch.index.query.BoolQueryBuilder;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.SearchHit;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.elasticsearch.search.sort.FieldSortBuilder;import org.elasticsearch.search.sort.SortOrder;
其他语言的就不帖了,可以到官方站点寻找。感觉官方还是有所保留就是。使用Elasticsearch High Level写查询,相比较于sql,会有一种强烈的不适感,应该有现成的工具可以将sql脚本转化为elasticsearch High level对应的查询代码吧,在这里简单晒一下查询代码的一点神态。
BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery();boolBuilder.must(QueryBuilders.termsQuery("title", “ChinaHadoop”));boolBuilder.must(QueryBuilders.termsQuery("content","公众号"))
不要太惊讶,就是这么晦涩与不爽的节奏!写习惯的sql,再来写这种“奇葩”的查询代码,是不是有种“生无可恋”的感受?不用太担心,关注ChinaHadoop公众号,回复”Elasticsearch”可获取一份小白 demo,初始化High Level API Client,定位index,type,多种查询条件代码,覆盖常见查询场景,完全不用烧脑,享受ChinaHadoop干货经验,快速打造自己的搜索引擎!
本文从应用的角度介绍了如何运用Elaticsearch搭建自主的搜索引擎解决方案,从环境安装、索引建立、同步索引数据,到使用Elastic High Level API进行数据查询,覆盖了一个简易自主搜索引擎的全生命周期,小白可参考本文实现一个自主搜索引擎,遇到问题可回复ChinaHadoop,得到指导与帮助。
关注ChinaHadoop 走进大数据实战

技术岛公众号
赞助商广告
