
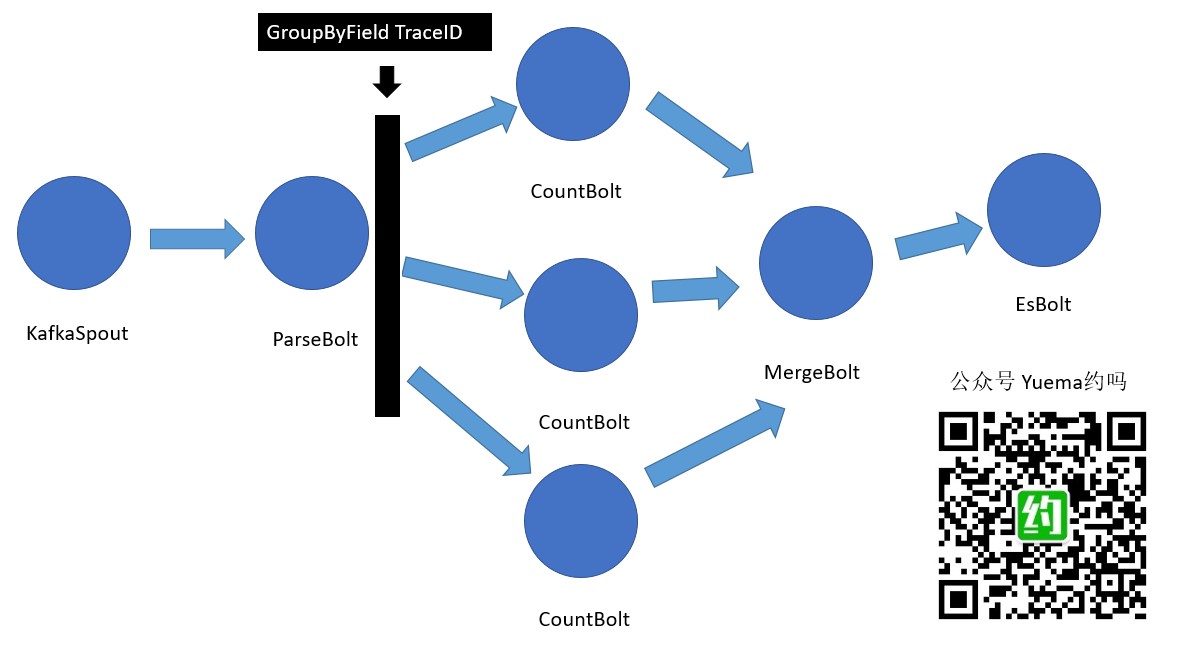
Storm & kafka 日志统计代码流程转成多个Bolt
所谓一图击破迷团。我们使用kafkaSpout接上kafka消息队列消息,使用ParseBolt将kafka消息中的message拿出来,得到我们统计日志要使用的日志节点信息traceId(跟踪Id)、日志时间、日志类型等信息,ParseBolt仅干这件事,把拿到的日志节点信息emit出去!抵达下一个CoutBolt,采用了GroupByField进行数据流控制,将同traceId的 tuple送到一个Bolt处理。CountBolt处理会进行日志合并统计,这个CountBolt有点点肥大,目前还没有再拆,统计逻辑在这个CountBolt里面。达到一定周期后,会将自身的统计数据emit出去,抵达MergeBolt,MergeBolt只做合并,将CountBolt节点的数据进行合并,达到一定周期后,将合并好的数据emit出去,抵达EsBolt,EsBolt将结果写入ElasticSearch。
QA1:为什么我们要用TraceID进行流控制?
因为一条日志只记录接口收到的时间或响应时间,需合成一对,得到处理时长。
QA2:GroupByFeild怎么感觉理解起来很怪异?
是的,如果新接触Storm,会听到一堆新词汇,Spout,Bolt,Topology,minbus,supervisor,worker,task等等。感觉用路由来理解这里的GroupByFeild按字段分组数据流,可能会比较好理解,至少我是这么觉得的。
QA3:Bolt到底拆分成几个好?
其实,刚开始的时候,我是打算一个KafkaSpout,一个Bolt,先把业务逻辑整出来,再来拆。不管拆成多少个Bolt,完成业务所需要的逻辑步骤一个都不能少,不管怎么拆。一方面刚玩Storm,也得找感觉。写完整理逻辑后,再针对性感受一下拆开处理会有哪些问题,能不能拆?拆完之后有什么好处,拆成多个Bolt后,数据怎么合并,为什么要拆。反复推敲之后,得到大神指点,也考虑后续集群运行的计算资源使用率,得提高吞吐量是更好。将EsBolt单拿出来,主要考虑合并数据逻辑与Es操作逻辑本身就两个人写,拆开也好开发,逻辑也清晰。
QA4:还可以怎么拆?
CountBolt逻辑有两大逻辑,一是日志合二为一,二是请求计数,时长计数。日志合二为一,将收发时间组成对,得到单个请求时长,这个逻辑与计数可以相互独立出来。即CountBolt拆成ReformBolt+CountBolt,Reform仅对日志进行合二为一,CountBolt仅统计。想想是不是这样子?
QA5:并行度怎么调优?
这个暂时没有太多的经验,初步来看,EsBolt可能着重考虑一下,应该要做到批量插入。网上有小伙伴已经踩进一条一条插入到hbase超时的坑。Es看起来也类似。更详细的并行度分享,等我后续实战后再分享。
Storm让人开心的是,这种Bolt串起来的方式,很有趣,感觉非常适合做可视化编程控制,不仅仅是用在Storm上,可以将程序按这种思想拆起一个一个Bolt小球,通过可视化的界面来配置逻辑流程,相当于可视化编程或者可视化生成Storm Topology,想想都非常有意思。
今天的实战分享就到这里啦,每天都会分享工作中实战的点点滴滴,并不能保证自己当前的做法就是百分之百正确或合理,敬请指教。
